Introduction
This is an in-depth analysis of the reasons that led to the COVID-19 positive results Excel error of the NHS Test and Trace system. The analysis is done using knowledge that a student can gain after studying a series of computing short courses at City, specifically Applied MS Excel, the series of VBA in Excel courses and the Database Design with SQL Server short course.
We have collated information published by the government and reported by news media to recreate, as faithfully as possible, the process that failed importing all COVID-19 positive test results.
We are also recommending steps that every company should follow when importing data from external partners, and the learning path prospective computing short courses students should take to gain enough knowledge to solve similar integration problems effectively.
Background
On Monday 5th October 2020 UK newspapers were reporting of a technical error in NHS’s test-and-trace system. The error meant that more than 15,000 positive cases of COVID-19 infections between 25th September and 2nd October were not included in daily statistics and thousands of people who had come in contact with infected individuals were not alerted.
In this post we are going to focus on the technological aspects of the error. We will try to figure out what might have gone wrong, by putting together information published by the government and newspapers and will give recommendations on what you can do to avoid facing similar errors when importing third party data or integrating your systems with external partners.
Information gathering
We will base our assumptions on a note describing the methodology used for COVID-19 testing data, published by the UK government [gov.uk-note]. It appears that testing is categorised into four pillars. According to the Mirror [Mirror], the error happened while handling ‘Pillar 2’ data. According to [gov.uk-note], pillar 2 is testing for the wider population collected by commercial partners. The dataset for pillar 2 testing comprises of:
- nose and throat swabs, which are counted together as one sample
- tests counted as they are dispatched
- ‘in-person’ tests processed through laboratories, excluding the ones counted at dispatch
- positive cases.
According to the note, there have been a couple of revisions to pillar 2 metrics and methodologies.
On the positive test results, which was the dataset where the error occurred, methodology was updated on 2nd July to remove duplicates across pillars 1 and 2, to ensure that a person who tests positive is only counted once. Specifically for England, the lab surveillance system for pillar 1 and 2 results removes duplicate records by running a complex algorithm that identifies individuals and only uses their first positive result for the metric. The algorithm uses the following properties to uniquely identify an individual:
- NHS Number
- Surname and Forename
- Hospital Number
- Date of Birth
- Postcode
News media presented a series of explanations of what is believed that had gone wrong.
- According to Daily Mirror and Daily Mail, “Excel spreadsheet reached its maximum size” [Mirror] [Mail]
- Daily Mirror also reports that “Outdated Excel spreadsheet format that was not capable of displaying all the lines of data” was the issue. [Mirror2]
- Daily Telegraph [Telegraph] goes into more details: “The problem emerged in a PHE (Public Health England) legacy system. Public Health England was reportedly using an automatic process to pull the testing data it received from commercial firms carrying out virus swabs into Excel templates. But the old Excel file format being used – XLS – could only handle 65,000 data rows. The files have now been split into smaller multiple files to prevent the issue happening again”.
- The Guardian [Guardian] on the other hand reports that the process is not completely automated and a lot of work is still done manually. It appears that CSV files are sent from labs to PHE, which are then loaded into Excel.
- Finally, BBC reports that each test result created several rows of data. In the same article, there is also a comparison between the XLS and XLSX file formats of Excel, claiming that the new format would be able to handle 16 times more cases than the older XLS one. [BBC]
In depth analysis of what caused the COVID-19 Excel error
Public Health England has not yet published exact details of what went wrong. What we will do is to try and simulate what might have happened, by putting together pieces of information from the governmental website and news media reports.
To do so, we will create a dummy CSV file that contains the properties(fields) [wikipedia-csv] used as unique identifiers for each person tested, together with some dummy fields that represent test results. We will then go through the most plausible scenarios and discuss what could have gone wrong, to produce the error experienced by the NHS Test-and-trace team.
A CSV file is a text file that represents tabular data. This means that it contains a specific number of columns and one or more rows. According to the basic rules for CSV files [wikipedia-csv] and the 2005 technical standard RFC4180 which formalises the CSV file format, “All records should have the same number of fields, in the same order”.
This is an example of what data would definitely exist in the CSV file (first represented as a table and then in CSV format – Disclaimer: NHS numbers are random):
| NHS Number |
Surname |
Forename |
Hospital number |
Date of Birth |
Postcode |
| 485 777 3456 |
Smith |
John |
HN3829904 |
12/03/2001 |
HD7 5UZ |
| 943 476 5919 |
Smith |
Jane |
|
21/12/1958 |
HD7 5UZ |
This is a CSV representation of the above tabular data:
NHS Number,Surname,Forename,Hospital number,Date of Birth,Postcode
485 777 3456,Smith,John,HN3829904,12/03/2001,HD7 5UZ
943 476 5919,Smith,Jane,,21/12/1958,HD7 5UZ
Further columns could be added to represent test results, but each row (record) should have values for each column (or at least simply a comma if a value is missing).
In order to test importing CSV files that are very large for Excel to handle, we created a dummy CSV file with 1,050,001 rows that has the following fields: NHS Number, Surname, Forename, Hospital number, Date of Birth, Postcode, Test number, Test result. The number of rows is larger than the limit of 1,048,576 rows that newer versions of Excel have [Excel-limitations].
The file contains random data that do not conform to data types of individual attributes. Specifically, the NHS Numbers generated are 10 random digits, where the 10th digit is not the control digit, postcodes simply follow the rule of having two letters-one or two numbers-space-one number-two letters format to look like postcodes but are not verified to be valid postcodes. You can download the dummy file from our Covid-19 Excel error analysis GitLab repository, where you will also find the Excel VBA code used to generate the test data.
Importing a CSV file that Excel cannot handle
Let’s try to import the generated CSV file into Excel. We do not know the version of Excel PHE is using, so we are going to go with the latest Excel 2019. News reports do mention that XLSX format could be used, so we assume PHE is using an Excel version after Excel 2007, but we are expecting similar error messages will appear in all Excel versions.
Opening CSV file directly in Excel
Here we see the error message we get if we try to open the generated CSV file directly in Excel. The way we opened it was by double clicking on the CSV file in the File Explorer, as the CSV extension is associated with MS Excel automatically during typical installation. An alternative way of opening the CSV file from within Excel would be to use the Open dialog, navigate to the directory that the CSV file is stored in and open the file from there.
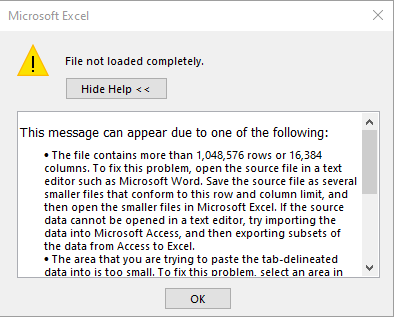
The error explains clearly that when the user clicks OK, Excel will truncate the file and only show the part that fits the rows and columns available in one worksheet.
Importing CSV using Power Query (also called Get and Transform or Get Data)
If the user tries to use this new Excel functionality to import the CSV file she will be faced with the following error:

Again here we see a very clear error message, which explains that when the user clicks OK the data will be truncated and Excel will only display as much data as it can fit in a worksheet. Clicking Cancel will not import any data at all.
We see that both ways of opening a file in Excel, without using VBA code, show an error message notifying the user that data will be truncated. Clicking OK and continuing with only the data that fit in a worksheet is obviously human error.
Importing CSV using VBA in Excel
News reports mention that there is a (semi)automatic way of importing data in CSV format. Such automation can be done in many different ways. One automation could be that the user opens the CSV file normally and then, using a central dashboard, instructs Excel which worksheet represents the CSV file that was just opened and should be imported. A variation of this kind of automation could be that the user points to a Table in Excel as the input that represents the imported CSV file (a Table is created when Power Query is used to import a CSV file). Both of these scenarios expect the user to open the file with one of the ways we describe above.
Another way of importing a CSV file would be using Visual Basic for Applications (VBA) code in Excel. Again here there are many valid ways that VBA code can be written to import text files. In order to test this scenario, we created a VBA subroutine that reads a CSV file one row at a time. Each row that is read is split into attribute values and entered in the next available row of a worksheet. No error handling was implemented in the code.
Below you can see the type of error the user would get if the CSV file was imported via VBA code. This is the error message shown by the VBA interpreter:
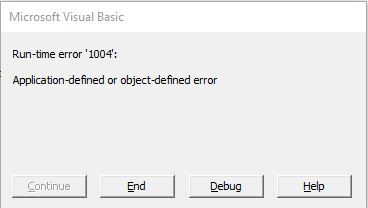 This error message is definitely a lot more cryptic than the two errors seen above. The choice of buttons is also quite difficult to work with, by an untrained user. I am not sure whether the user would click on “Help” (only to get further unhelpful information – as shown below), or simply click “End” to stop the execution of the VBA automation. I am fairly certain though that either way the thought that first came to the user’s mind would be “HELP! I don’t know what to do.”.
This error message is definitely a lot more cryptic than the two errors seen above. The choice of buttons is also quite difficult to work with, by an untrained user. I am not sure whether the user would click on “Help” (only to get further unhelpful information – as shown below), or simply click “End” to stop the execution of the VBA automation. I am fairly certain though that either way the thought that first came to the user’s mind would be “HELP! I don’t know what to do.”.
 In every way we see this, an error message would have appeared on screen, which means a user clicked OK without understanding the implications, possibly due to no relevant training. There is one possibility that the user importing the CSV file might have not been shown an error message. In this scenario, a VBA developer chooses to suppress all error messages shown from the VBA interpreter (like the one above). This is usually done either in an effort to avoid scaring the end user, believing that no error messages will be thrown by the VBA code written and if any is thrown it won’t affect the end result. In this case, human error is still the cause of the truncated dataset. However it is not the end user importing the CSV file that caused the error, but the VBA developer.
In every way we see this, an error message would have appeared on screen, which means a user clicked OK without understanding the implications, possibly due to no relevant training. There is one possibility that the user importing the CSV file might have not been shown an error message. In this scenario, a VBA developer chooses to suppress all error messages shown from the VBA interpreter (like the one above). This is usually done either in an effort to avoid scaring the end user, believing that no error messages will be thrown by the VBA code written and if any is thrown it won’t affect the end result. In this case, human error is still the cause of the truncated dataset. However it is not the end user importing the CSV file that caused the error, but the VBA developer.
Remarks on the process
Storage structure of test results in CSV file
BBC [BBC] reports that each test result generates more than one row of data. We have two interpretations of what this could actually mean, based on the fact that data is delivered in CSV format.
- Each test generates time based results, i.e. one value in 30 minutes, another value in 90 minutes etc. and the decision whether the test is positive or negative comes after a simple calculation between these values.
- The process was misunderstood by the reporter. What really was meant is that in the same dataset there might be two tests (with two individual test IDs) for the same patient. This might happen if for example the first test became contaminated or a second test was done the same day for whatever reason.
As mentioned in Wikipedia “CSV formats are best used to represent sets or sequences of records in which each record has an identical list of fields. This corresponds to a single relation in a relational database, or to data in a typical spreadsheet”. The relational model used in relational databases and spreadsheets is most often represented as a table, where a header defines the attribute(field) names and each row has attribute values for each attribute name. In the relational model each row represents a unique record. This is the reason we are sceptical about the premise that a test result generates more than one row of data. Each row needs to be unique in some way, by a combination of attribute values. The use of a relational format to represent data that are not following the relational model does not make sense. This is how our assumption was made that each result must be unique either by including a timestamp or some other unique identifier or attribute, if two or more rows of the dataset are for the same test. On the other hand, we believe it is catastrophic if two rows cannot be uniquely identified as an individual entity, but still give two values for the same attribute.
Use of CSV for transportation of results
CSV is a very widely used format. It is not known when it was first created, but it already existed in 1972 [IBM-Fortran]. Even though it has been used for at least five decades, CSV support is varying across software. Its flexibility means that it is very easy to create CSV files that do not conform to all expected characteristics of CSV files. It is also very easy to break. A badly generated CSV file with the wrong value for one of its attributes, for example a comma to denote thousands in a number, i.e. 1,532.25, would not be imported correctly by any software, unless a different separator was used instead of a comma, a practice that is quite common. Usually the structure of CSV files is documented within a project, so that both the exporting and importing applications can correctly support the files generated.
Taking into consideration the limitations and old age of CSV format, as well as the potential duplication of data between multiple rows in the CSV file, we believe a different file format should be used (e.g. XML or JSON).
Use of Excel
There has been a lot of criticism on the use of Excel for COVID-19 test results, given that PHE already has a robust database, used for years, to collate test results for various diseases [Sky-news]. From this Sky News article we see that Pillar 2 data are probably the only data not directly sent to the database. It appears that Excel is used to open and upload the CSV data to the database.
Is the use of Excel valid in the case of getting COVID-19 test results from Pillar 2 privately-run labs and converting them and sending them to the main PHE database? We need to think of all the requirements and limitations that existed at the time of conception of this use of Excel, before we decide:
- First of all, in March 2020, with the need to increase COVID-19 tests rapidly, privately-run labs were set up. We believe that each lab is using its own software to record test results. It is expected that most if not all of this software was able to export to CSV format quite easily, maybe with minimal set up.
- Second, uploading data to any database needs to pass some validation, so that the database does not become corrupt. Such checks are best performed on the side of the database, instead of the side of the user – where user is each lab.
- Third, new software needed to be created in almost no time to be able to handle the data sent by the labs. It would also need to be used by users that would require almost no new training. This means that an extension for a software that users already know how to use is the best option.
Excel is probably the software all PHE users knew how to use, in varying degrees, depending on their position. For time zero, a VBA extension in Excel seems like the first logical step. Excel VBA is commonly used as a rapid application development tool to test an idea.
VBA is a quite flexible language that, by leveraging the power of Excel, can help create very powerful extensions in very short time. We believe a very first version of a VBA extension that could handle CSV files sent by private labs could be created in a few hours, to handle the first data coming in, needing processing and uploading to the database.
Once a primitive way of importing data was set up, two parallel processes should have begun:
- One should revise, expand and vigorously test functionality of the VBA extension, with a focus to eliminate human error from the process as much as possible.
- The other should be to create an implementation that bypasses Excel all together and allows privately-run labs to use it to upload test results directly. A great way to do so would be through a restricted secure web service.
We believe that if the importing VBA process was correctly designed and tested, even an old version of Excel from 20 years ago could handle any CSV file size. The limitation of 65,536 rows that Excel has for each worksheet is not something that should stop an experienced VBA developer in creating a robust VBA add-in that can import CSV files of any size.
- If the contents of the CSV file are converted by an Excel template to be uploaded to the PHE database, then the VBA procedure should read in memory one row of data at a time and upload it, instead of importing the whole file in a worksheet. This approach has two limitations. The amount of RAM available on the PC to hold one row of data in memory and the amount of hard disk space available to allow storing the CSV file. We believe that both of these are sufficient on the PC where the error occurred, given that it successfully loaded sixty five thousand rows into Excel.
- If the user needed to view the raw data of the CSV file in Excel then, depending on the screen size, only about a hundred rows of data would need to be displayed at any one time. This can be achieved using a sliding window technique. Again, this is something that Excel could handle in pre-2007 versions, as it is far lower than the 65,536 rows available.
Our conclusion is that Excel was correctly used as a solution that satisfied all requirements at the time. A correctly designed and implemented Excel VBA add-in is also able to handle any number of rows from a CSV file.
What should you do to avoid this happening to your company?
Let’s explore best practices when importing data and integrating processes with an external company. If your company is collaborating with an external partner and prepares to import their data, then you need to have a bulletproof process to handle the incoming data. It is important to create an automated process and remove user involvement as much as possible to minimise or even eliminate human error. It is very important to test your automation vigorously, especially at edge cases and around known limitations.
If you are starting a new partnership and you want to test a satisfactory integration solution before implementing a full system that will cost a lot, Excel is a great choice. Most IT users already have some exposure to Excel. With minimal training you can train your end users to use VBA add-ins. Excel has grown and matured to become a tool that can handle any amount of data, limited only by system resources, provided that data is loaded judiciously.
You need a specialist that understands data, Excel, VBA and databases in depth.
What computing short courses will provide required knowledge?
A computing short courses student that has taken Excel, VBA and Database short courses will be able to design and implement a system that can import any amount of data from a CSV file into Excel and store it in a large database. Our recommended learning path would be:
Conclusion
A robust automated system could have been created using Excel and VBA to handle importing of COVID-19 test results from CSV files of any size. Both Excel and VBA are able to handle this, if the automation is correctly designed, implemented and tested. A computing short courses student that has studied City’s Applied MS Excel for Business course, VBA in Excel series of short courses and optionally the Database Design course would have enough knowledge to design and implement such a system.
Furthermore, if end users of the NHS Test and Trace system were trained on the way the CSV importing automation works for COVID-19 test results from privately-run labs, they would be able to alert immediately that one of the CSV files could not be handled by the automation, saving precious time in the tracing of contacts of infected individuals.
We conclude that it was definitely human error that caused the COVID-19 positive cases to be missed, either at the user level while importing the data, or at a developer level where limitations of Excel were not taken into account. A well informed and trained Excel VBA specialist would be able to design and implement a CSV import and conversion system correctly.
References
[BBC] https://www.bbc.co.uk/news/technology-54423988, retrieved 10/Oct/2020.
[Excel-limitations] https://support.microsoft.com/en-us/office/excel-specifications-and-limits-1672b34d-7043-467e-8e27-269d656771c3, retrieved 10/Oct/2020.
[gov.uk-note] https://www.gov.uk/government/publications/coronavirus-covid-19-testing-data-methodology/covid-19-testing-data-methodology-note, retrieved 10/Oct/2020.
[Guardian] https://www.theguardian.com/politics/2020/oct/05/how-excel-may-have-caused-loss-of-16000-covid-tests-in-england, retrieved 10/Oct/2020.
[IBM-Fortran] http://bitsavers.trailing-edge.com/pdf/ibm/370/fortran/GC28-6884-0_IBM_FORTRAN_Program_Products_for_OS_and_CMS_General_Information_Jul72.pdf, retrieved 10/Oct/2020.
[Mail] https://www.dailymail.co.uk/news/article-8805697/Furious-blame-game-16-000-Covid-cases-missed-Excel-glitch.html, retrieved 10/Oct/2020.
[Mirror] https://www.mirror.co.uk/news/politics/16000-coronavirus-tests-went-missing-22794820, retrieved 10/Oct/2020.
[Mirror2] https://www.mirror.co.uk/news/politics/spreadsheet-blunder-meant-48000-potentially-22797866, retrieved 10/Oct/2020.
[Sky-News] https://news.sky.com/story/coronavirus-data-can-save-lives-data-can-cost-lives-and-this-latest-testing-blunder-will-likely-prove-it-12090904, retrieved 10/Oct/2020.
[Telegraph] https://www.telegraph.co.uk/technology/2020/10/05/excel-error-led-16000-missing-coronavirus-cases/, retrieved 10/Oct/2020.
[wikipedia-csv] https://en.wikipedia.org/wiki/Comma-separated_values, retrieved 10/Oct/2020.
About the author
Dionysis Dimakopoulos is the subject coordinator for the computing short courses at City, University of London. He has been teaching Visual Basic for Applications in Excel since 2003. He is an experienced software engineer, IT integrations consultant and published researcher. He has decades of experience creating systems that combine the power of web services with the familiar interface of Excel for engineering or financial applications, or offer interoperability with Office and other applications. His latest work is on the Learning Designer, an open online learning design tool for teachers in all sectors of education and subject areas, used around the globe, where he is the lead developer.























Recent Comments